1.1 Understanding Cloud Manager Orchestration Architecture
This section contains information about the following topics:
1.1.1 The Orchestration Server
The NetIQ Cloud Manager Orchestration Server is an advanced datacenter management solution designed to manage all network resources. It provides the infrastructure that manages group of ten, one hundred, or thousands of physical or virtual resources.
The Orchestration Server can perform a wide range of distributed processing problems including high performance computing, and breaking down work, including VM life cycle management, into jobs that can be processed in parallel through distributed job scheduling.
The following figure shows a high-level perspective of how the Orchestration Server fits into Cloud Manager architecture.
Figure 1-1 Cloud Manager Orchestration Artchitecture
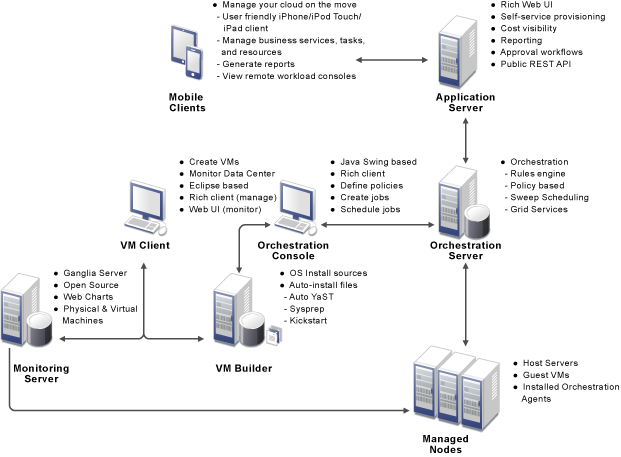
The Orchestration Server is the gateway between enterprise applications and resource servers. The server has two primary functions:
-
To manage the resource servers
-
To manage jobs to run on the computing resource
In the first function, the server manages the computing resources by collecting, maintaining, and updating their status availability, service cost, and other facts. Changes to the computing resources can be made by the administrator.
The second function of the server is to run remote applications—called jobs—on the computing resources. The Orchestration Server uses a policy-based broker and scheduler to decide when and how a job should run on the computing resources. The decisions are based on many controlled factors, including the number of computing resources, their cost, and a variety of other factors as specified by the policy constraints set up by the server administrator. The Orchestration Server runs the job and provides all the job’s output responses back to the user. The server provides failover capabilities to allow jobs to continue if computing resources and network conditions degrade.
The core strength of the Orchestration Server is the capability to automatically, rapidly, and securely create and scale heterogeneous virtual environments by using specialized VM provisioning adapter jobs that discover VMs already existing in various hypervisor environments, such as VMware, Microsoft Hyper-V, Citrix XenServer, Xen, and KVM. Once the VMs are discovered, they can be cloned and then provisioned as workloads to suit the business service needs of Cloud Manager users.
1.1.2 The Orchestration Agent
Agents are installed on all managed resources as part of the product deployment. The agent connects every managed resource to its configured server and advertises to the Orchestration Server that the resource is available for tasks. This persistent and auto-reestablishing connection is important because it provides a message bus for the distribution of work, collection of information about the resource, per-job messaging, health checks, and resource failover control.
After resources are enabled, Cloud Manager Orchestration can discover, access, and store detailed abstracted information—called “facts”—about every resource. Managed resources, referred to as “nodes,” are addressable members of the Orchestration Server “grid” (also sometimes called the “matrix”). When integrated into the grid, nodes can be deployed, monitored, and managed by the Orchestration Server, as discussed in Section 1.2, Understanding Orchestration Functionality.
An overview of Cloud Manager Orchestration grid architecture is illustrated in the figure below, much of which is explained in this guide:
Figure 1-2 Cloud Manager Orchestration Grid Architecture

1.1.3 The Resource Monitor
Cloud Manager Orchestration enables the monitoring of your system computing resources by using its built-in Resource Monitor.
1.1.4 The Orchestration Console and Command Line Tools
The Orchestration Console and the Orchestration command line tools (sometimes called the “Orchestration Clients”) let a computing resource administrator troubleshoot, initiate, change, or shut down server functions for the Orchestration Server and its computing resources. The clients also monitor all managed computing resource job activity and provide facilities to manage application jobs. When you install the Clients on a computing resource, you are installing the following tools:
-
zos command line interface
-
zosadmin command line interface
-
Orchestration Console
-
Java SDK (toolkit)
The Orchestration Console is a graphical user interface running on Java. It provides a way for the server administrator to troubleshoot and to initiate, change, or shut down the functioning of the Orchestration Server and its resources. It also functions as a monitor of all Orchestration job activity, and it provides an interface for managing Orchestration Server jobs. For more information about the console, see the NetIQ Cloud Manager 2.1.5 Orchestration Console Reference.
1.1.5 Entity Types and Managers
The following entities are some of key components of the Orchestration Server model:
Resources
All managed resources, which are called nodes, have an agent with a socket connection to the Orchestration Server. All resource use is metered, controlled, and audited by the Orchestration Server. Policies govern the use of resources.
The Orchestration Server allocates resources by reacting as load is increased on a resource. As soon as we go above a threshold that was set in a policy, a new resource is allocated and consequently the load on that resource drops to an acceptable rate.
You can also write and jobs that perform cost accounting to account for the cost of a resource up through the job hierarchy, periodically, about every 20 seconds. For more information, see Auditing and Accounting Jobs.
A collection of jobs, all under the same hierarchy, can cooperate with each other so that when one job offers to give up a resource it is reallocated to another similar priority job. Similarly, when a higher priority job becomes overloaded and is waiting on a resource, the system “steals” a resource from a lower priority job, thus increasing load on the low priority job and allocating it to the higher priority job. This process satisfies the policy, which specifies that a higher priority job must complete at the expense of a low priority job.
Users
An Orchestration user is an individual who authenticates to the Orchestration Server for the purpose of managing (that is, running, monitoring, canceling, pausing, stopping, or starting) a deployed job, or a user who authenticates through the to manage virtual machines. The Orchestration Server administrator can use the Orchestration Console to identify users who are running jobs and to monitor the jobs that are currently running or that have run during the current server session.
Orchestration Server users must authenticate to access the system. Access and use of system resources are governed by policies. For more information, see The User Object
in the NetIQ Cloud Manager 2.1.5 Orchestration Console Reference.
Job Definitions
A job definition is described in the embedded enhanced Python script that you create as a job developer. Each job instance runs a job that is defined by the Job Definition Language (JDL). Job definitions might also contain usage policies.
Job Instances
Jobs are instantiated at runtime from job definitions that inherit policies from the entire context of the job (such as users, job definitions, resources, or groups).
Policies
Policies are XML documents that contain various constraints and static fact assignments that govern how jobs run in the Cloud Manager Orchestration environment.
Policies are used to enforce quotas, job queuing, resource restrictions, permissions, and other job parameters. Policies can be associated with any Orchestration Server object.
Facts
Facts represent the state of any object in the Orchestration Server grid. They can be discovered through a job or they can be explicitly set.
Facts control the behavior a job (or joblet) when it’s executing. Facts also detect and return information about that job in various UIs and server functions. For example, a job description that is set through its policy and has a specified value might do absolutely nothing except return immediately after network latency.
The XML fact element defines a fact to be stored in the Grid object’s fact namespace. The name, type and value of the fact are specified as attributes. For list or array fact types, the element tag defines list or array members. For dictionary fact types, the dict tag defines dictionary members.
Facts can also be created and modified in JDL and in the Java Client SDK.
There are three basic types of facts:
-
Static: Facts that require you to set a value. For example, in a policy, you might set a value to be False. Static facts can be modified through policies.
-
Dynamic: Facts produced by the Orchestration Server system itself. Policies cannot override dynamic facts. They are read only and their value is determined by the Orchestration Server itself.
-
Computed: Facts derived from a value, like that generated from the cell of a spreadsheet. Computed facts have some kind of logic behind them which derive their values..
See the example, /opt/novell/zenworks/zos/server/examples/allTypes.policy. This example policy has an XML representation for all the fact types.
Constraints
The constraint element of a policy can define the selection and allocation of Grid objects (such as resources) in a job. The required type attribute of a constraint defines the selection of the resource type.
For example, in order for the Orchestration Server to choose resources for a job, it uses a “resource” constraint type. A resource constraint consists of Boolean logic that executes against facts in the system. Based upon this evaluation, the Orchestration Server considers only resources that match the criteria that have been defined in constraints.
Groups
Resources, users, job definitions and virtual machines (VM) are managed in groups with group policies that are inherited by members of the group.
VM: Hosts, Images, and Instances
A virtual machine host is a resource that is able to run guest operating systems. Attributes (facts) associated with the VM host control its limitations and functionality within the Orchestration Server. A VM image is a resource image that can be cloned and/or provisioned. A VM instance represents a running copy of a VM image.
Templates
Templates are images that are meant to be cloned (copied) prior to provisioning the new copy.
1.1.6 Jobs
The Orchestration Server manages all nodes by administering jobs (and the functional control of jobs at the resource level by using joblets), which control the properties (facts) associated with every resource. In other words, jobs are units of functionality that dispatch data center tasks to resources on the network such as management, migration, monitoring, load balancing, etc.
The Orchestration Server provides a unique job development, debugging, and deployment environment that expands with the demands of growing data centers.
As a job developer, your task is to develop jobs to perform a wide array of work that can be deployed and managed by the Orchestration Server.
Jobs, which run on the Orchestration Server, can provide functions within the Orchestration environment that might last from seconds to months. Job and joblet code exist in the same script file and are identified by the .jdl extension. The .jdl script contains only one job definition and zero or more joblet definitions. A .jdl script can have only one Job subclass. As for naming conventions, the Job subclass name does not have to match the .jdl filename; however, the .jdl filename is the defined job name, so the .jdl filename must match the .job filename that contains the .jdl script. For example, the job files (demoIterator.jdl and demoIterator.policy) included in the demoIterator example job are packaged into the archive file named demoIterator.job, so in this case, the name of the job is demoIterator.
A job file also might have policies associated with it to define and control the job’s behavior and to define certain constraints to restrict its execution. A .jdl script that is accompanied by a policy file is typically packaged in a job archive file (.job). Because a .job file is physically equivalent to a Java archive file (.jar), you can use the JDK JAR tool to create the job archive.
Multiple job archives can be delivered as a management pack in a service archive file (SAR) identified with the .sar extension. Typically, a group of related files are delivered this way. For example, the Xen30 management pack is a SAR.
As shown in the following illustration, jobs include all of the code, policy, and data elements necessary to execute specific, predetermined tasks administered either through the Cloud Manager Orchestration Console, or from the zos command line tool.
Figure 1-3 Components of a Job (my.job,)
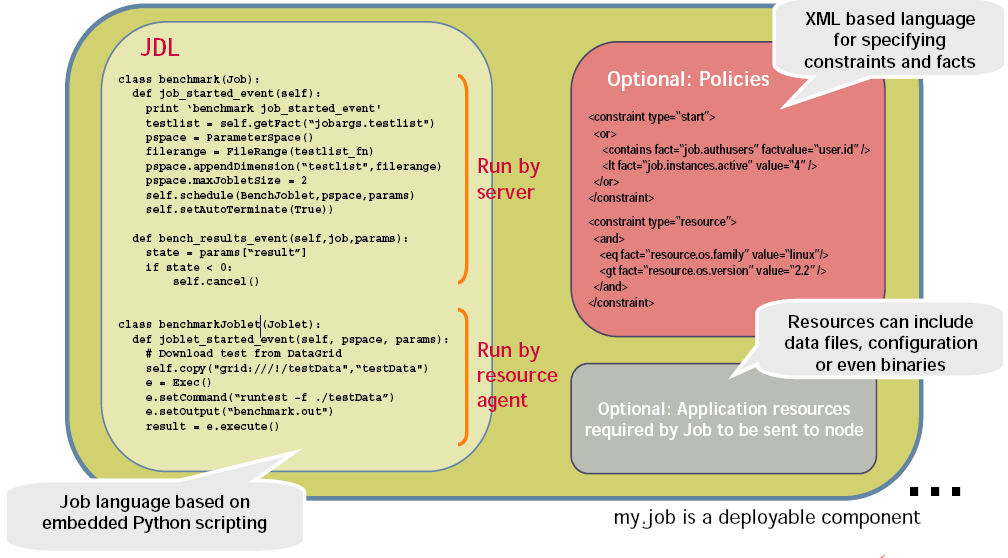
Because each job has specific, predefined elements, jobs can be scripted and delivered to any agent, which ultimately can lead to automating almost any datacenter task. Jobs provide the following functionality:
Controlling Process Flow
Jobs can written to control all operations and processes of managed resources. Through jobs, the Orchestration Server manages resources to perform work. Automated jobs (written in JDL), are broken down into joblets, which are distributed among multiple resources.
Parallel Processing
By managing many small joblets, the Orchestration Server can enhance system performance and maximize resource use.
Managing the Cluster Life Cycle
Jobs can detect demand and monitor health of system resources, then modify clusters automatically to maximize system performance and provide failover services.
Discovery Jobs
Some jobs provide inspection of resources to more effectively management assets. These jobs enable all agents to periodically report basic resource facts and performance metrics. In essence, these metrics are stored as facts consisting of a key word and typed-value pairs like the following example:
resource.loadaverage=4.563, type=float
Jobs can poll resources and automatically trigger other jobs if resource performance values reach certain levels.
The system job scheduler is used to run resource discovery jobs to augment resource facts as demands change on resources. This can be done on a routine, scheduled basis or whenever new resources are provisioned, new software is installed, bandwidth changes occur, OS patches are deployed, or other events occur that might impact the system.
Consequently, resource facts form a capabilities database for the entire system. Jobs can be written that apply constraints to facts in policies, thus providing very granular control of all resources as required. All active resources are searchable and records are retained for all off-line resources.
The following osInfo.job example shows how a job sets operating system facts for specific resources:
resource.cpu.mhz (integer) e.g., "800" (in Mhz)
resource.cpy.vendor (string) e.g. "GenuineIntel"
resource.cpu.model (string) e.g. "Pentium III"
resource.cpu.family (string) e.g. "i686"
osInfo.job is packaged as a single cross-platform job and includes the Python-based JDL and a policy to set the timeout. It is run each time a new resource appears and once every 24 hours to ensure validity of the resources..
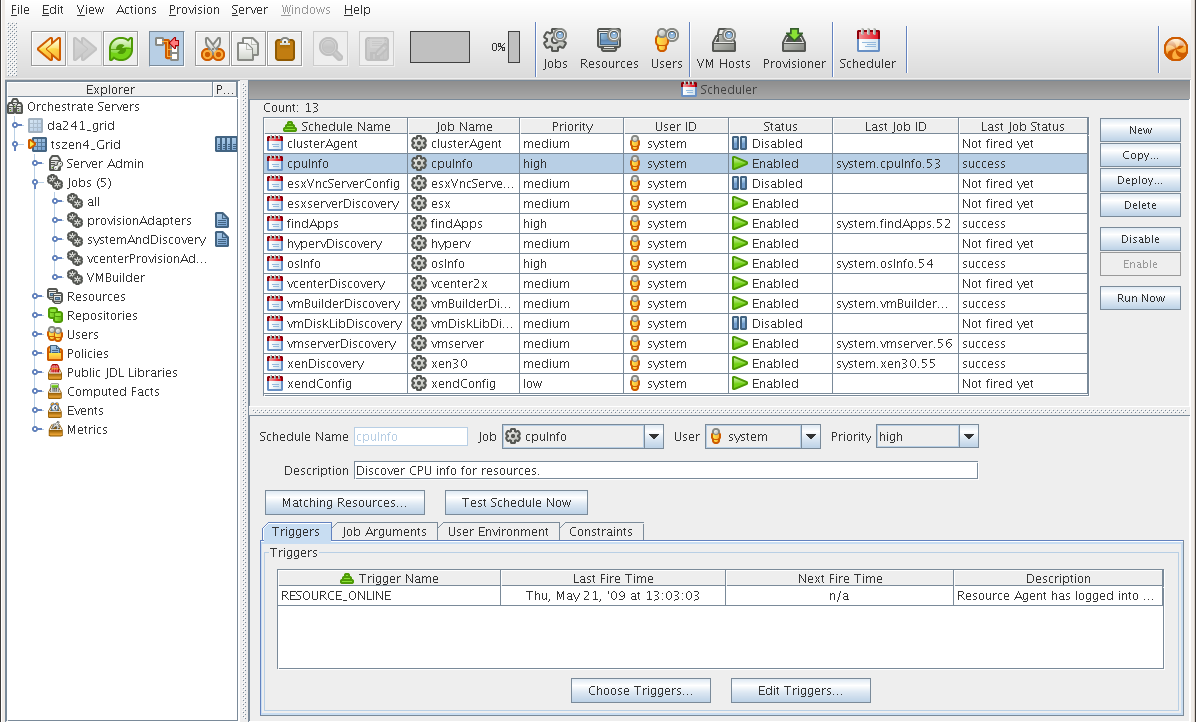
System Jobs
Jobs can be scheduled to periodically trigger specific system resources based on specific time constraints or events. As shown in the following figure, the Orchestration Server provides a built-in job scheduler that enables you or system administrators to flexibly deploy and run jobs.
Figure 1-4 The Job Scheduler
Provisioning Jobs
Jobs also drive provisioning for virtual machines (VMs) and physical machines, such as blade servers. Provisioning adapter jobs for various VM hypervisors are deployed and organized into appropriate job groups for management convenience.
The provisioning jobs included in the Orchestration Server are used for interacting with VM hosts and repositories for VM life cycle management and for cloning, moving VMs, and other management tasks. These jobs are called “provisioning adapters” and are members of the job group called “provisionAdapters.”
Auditing and Accounting Jobs
You can create Cloud Manager Orchestration jobs that perform reporting, auditing, and costing functions inside your data center. Your jobs can aggregate cost accounting for assigned resources and perform resource audit trails.
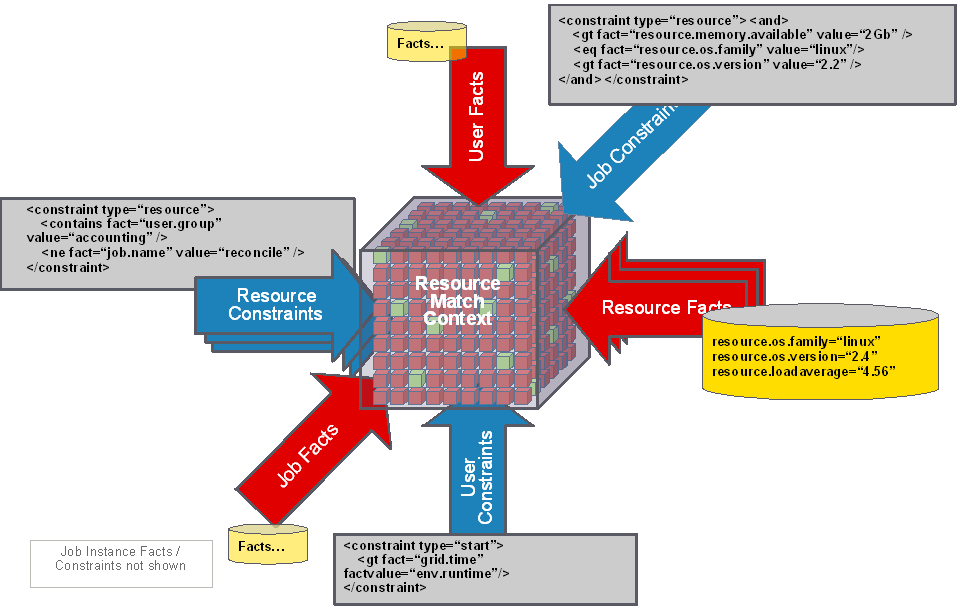
1.1.7 Constraint-Based Job Scheduling
The Orchestration Server is a “broker” that can distribute jobs to every “partner” agent on the grid. Based on assigned policies, jobs have priorities and are executed based on the following contexts:
-
User Constraints
-
User Facts
-
Job Constraints
-
Job Facts
-
Job Instance
-
Resource User Constraints
-
Resource Facts
-
Groups
Each object in a job context contains the following elements:
Figure 1-5 Constraint-Based Resource Brokering