4.8 Failback (conmutación a configuración previa)
El paso lógico siguiente tras un failover, es una operación de failback. Con ella se transfiere la carga de trabajo de failover a su infraestructura original o, si fuera necesario, a una nueva.
Los métodos de failback admitidos dependen del tipo de infraestructura de destino y del grado de automatización del proceso de failback:
-
Failback automatizado a una máquina virtual: compatible con plataformas VMware ESX y clústeres DRS VMware.
-
Failback semiautomatizado a un equipo físico: compatible con todos los equipos físicos.
-
Failback semiautomatizado a una máquina virtual: compatible con plataformas Microsoft Hyper-V.
En los temas siguientes se proporciona más información:
4.8.1 Failback automatizado a una plataforma de máquina virtual
Los contenedores siguientes se admiten como destinos de failback automatizados:
|
Destino |
Notas |
|---|---|
|
Clúster DRS VMware en vSphere 5.15 |
|
|
Clúster DRS VMware en vSphere 5.1 |
|
|
Clúster DRS VMware en vSphere 5.0 |
|
|
Clúster DRS VMware en vSphere 4.1 |
|
|
VMware ESXi 4.1, 5.0, 5.1 |
Las versiones ESXi deben disponer de una licencia pagada. La protección no se admite en estos sistemas si funcionan con una licencia gratuita. |
|
VMware ESX 4.1 |
|
Lleve a cabo estos pasos para ejecutar un failback automatizado de una carga de trabajo de failover en un contenedor VMware de destino.
-
Tras un failover, seleccione la carga de trabajo en la página Workloads (Cargas de trabajo) y haga clic en Failback.
El sistema solicita que se realicen las siguientes selecciones.
-
Especifique los siguientes conjuntos de parámetros:
-
Workload Settings (Configuración de la carga de trabajo): especifique el nombre de host o la dirección IP de la carga de trabajo de failover y proporcione las credenciales del nivel de administrador. Use el formato de credencial necesario (consulte Directrices para las credenciales de carga de trabajo y contenedor).
-
Failback Target Settings (Configuración de destino de failback): especifique los parámetros siguientes:
-
Replication Method (Método de réplica): seleccione el ámbito de la réplica de datos. Si selecciona Incremental, debe preparar un destino. Consulte Método de réplica inicial (completa o incremental).
-
Target Type (Tipo de destino): seleccione Virtual Target (Destino virtual). Si aún no tiene un contenedor de failback, haga clic en Add Container (Añadir contenedor) y añada al inventario un contenedor compatible.
-
-
-
Haga clic en Save and Prepare (Guardar y preparar) y supervise el progreso en la pantalla Command Details (Detalles del comando).
Cuando se complete correctamente, PlateSpin Protect cargará la pantalla Ready for Failback (Preparado para el failback), donde se le pide que especifique los detalles de la operación de failback.
-
Configure los detalles del failback. Consulte Detalles de failback (carga de trabajo en máquina virtual).
-
Haga clic en Save and Failback (Guardar y failback) y supervise el progreso en la página Command Details (Detalles del comando). Consulte la Figura 4-2.
PlateSpin Protect ejecutará el comando. Si ha seleccionado Reprotect after Failback (Volver a proteger después del failback) en el conjunto de parámetros posterior al failback, se muestra un comando Reprotect (Volver a proteger) en la interfaz Web de PlateSpin Protect.
Figura 4-2 Detalles del comando de failback
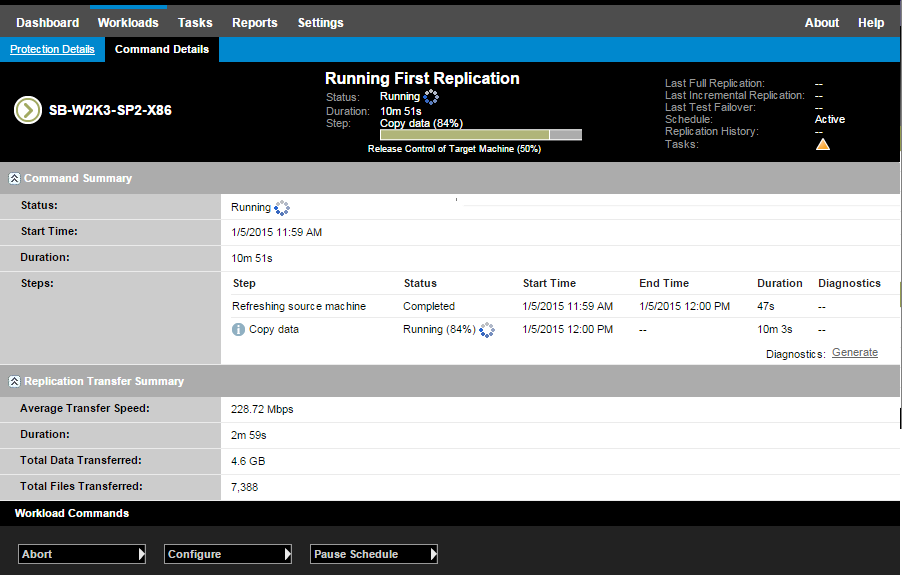
Detalles de failback (carga de trabajo en máquina virtual)
Los detalles del failback se representan mediante tres conjuntos de parámetros que se pueden configurar al realizar una operación de carga de trabajo de failback en una máquina virtual.
Tabla 4-2 Detalles de failback (máquina virtual)
|
Conjunto de parámetros (configuración) |
Detalles |
|---|---|
|
Failback |
Transfer Method (Método de transferencia): permite seleccionar un mecanismo de transferencia de datos y la seguridad mediante cifrado. Consulte Transferencia de datos. Failback Network (Red de failback): permite dirigir el tráfico de failback por una red dedicada basada en las redes virtuales definidas en el contenedor de máquina virtual. Consulte Redes. VM Datastore (Almacén de datos de máquina virtual): permite seleccionar un almacén de datos asociado con el contenedor de failback para la carga de trabajo de destino. Volume Mapping (Asignación de volumen): si el método de réplica inicial especificado es el incremental, permite seleccionar volúmenes de origen y asignarlos a volúmenes del destino de failback para su sincronización. Services/Daemons to stop (Servicios/Daemons que se deben detener): permite seleccionar los servicios de Windows o los daemons de Linux que se detendrán automáticamente durante el failback. Consulte Control de servicios y daemons. Alternative Address for Source (Dirección alternativa para el origen): acepta la introducción de una dirección IP adicional para la máquina virtual en failover, si fuera aplicable. Consulte Protección en redes públicas y privadas mediante NAT. |
|
Carga de trabajo |
Número de CPU: permite especificar el número necesario de CPU virtuales asignadas a la carga de trabajo de destino. VM Memory (Memoria de la máquina virtual): permite asignar la RAM necesaria a la carga de trabajo de destino. Hostname, Domain/Workgroup (Nombre de host, Dominio/Grupo de trabajo): use estas opciones para controlar la identidad y la afiliación de dominio/grupo de trabajo de la carga de trabajo de destino. Para la afiliación del dominio, se necesitan las credenciales del administrador del dominio. Network Connections (Conexiones de red): use estas opciones para especificar la asignación de red de la carga de trabajo de destino basada en las redes virtuales del contenedor de máquina virtual subyacente. Service States to Change (Estados de servicio que se deben cambiar): permite controlar el estado de inicio de servicios de aplicaciones (Windows) o daemon (Linux) específicos. Consulte Control de servicios y daemons. |
|
Después del failback |
Reprotect Workload (Volver a proteger la carga de trabajo): use esta opción si tiene previsto volver a crear el contrato de protección de la carga de trabajo de destino después de la distribución. Se mantiene así un historial continuo de eventos para la carga de trabajo y se asigna o de designa automáticamente una licencia de carga de trabajo.
|