6.1 Availability and Fault Tolerance
Some terms commonly used to describe a system’s maximum availability are: “24 (hours) by 7 (days),” “three-nines,” or “five-nines,” which describe the required percentage availability (99.9% or 99.999%).
High availability conveys the importance of keeping the system up and running as long as possible. High availability typically refers to the running state of an application. For Operations Center, it generally refers to the whole system as an entity that is available.
High availability has costs associated with it. For example, a system that can be down for 20 minutes for unscheduled outages during a week obviously costs less than one that can be down for 20 minutes over an entire month.
High availability is directly connected to fault tolerance. Fault tolerance usually indicates there is a system in place to ensure undisrupted system availability in the event of hardware or software failure. The type of fault tolerance employed determines the impact on availability if a component of the system fails.
The levels of fault tolerance vary. For example, mirrored drives are good; mirrored RAID drives are better; and dual servers with mirrored RAID drives are even better. Each step in improvement has a cost associated with it.
High Availability can be achieved using hardware and/or software. Some software is provided directly by the hardware manufacturer, while other technologies are add‑ons from third parties (hardware and/or software).
To implement high availability and fault tolerance, you should focus on these components:
-
Operations Center server
-
Management systems that integrate with Operations Center
-
Databases used by Operations Center for storing or obtaining data
-
Networking components (LAN and/or WAN)
A configuration that achieves high availability can include:
-
Dual (or more) servers for Operations Center (physical or clustered)
-
Dual (or more) management systems (OpenView, Netcool, etc.; physical or clustered)
-
Potentially dual networking components
Review the following sections for more information on server configurations:
6.1.2 Example
Figure 6-1 illustrates a Operations Center implementation that has high availability and fault tolerance.
Figure 6-1 Operations Center Configuration for High Availability and Fault Tolerance
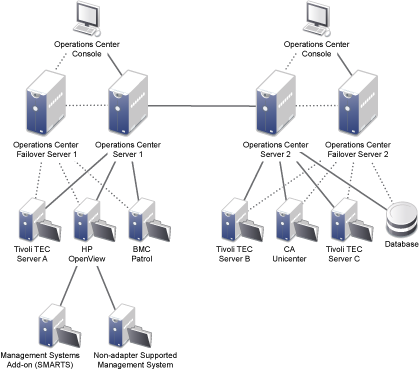
Users open a URL to operationscenter.myCompany.com, which sends the user to Operations Center server 1 (left side), or in the event of a failure, users are directed to Failover Operations Center server 1. This achieves the first level of fault tolerance and high availability.
Both Operations Center servers are configured and run at the same time (Hot/Hot) with the same data because of the dual connections to the underlying management systems. The assumption is that the underlying management systems are configured in the same manner.
One Operations Center server can also be configured with dual adapters connected to the primary and backup of each management system.