4.2 Understanding JDBC Identity Sources
For CloudAccess to provision user accounts to the SaaS applications, each user account in the identity source must contain the attributes listed. If you are using a JDBC database, there are certain columns of information that must be populated.
NOTE:To use the JDBC database as an identity source, you must know and understand JDBC databases. The information provided in this section is intended for database administrators.
Review the information in the following sections and ensure that your identity source meets all requirements and the user account information in the identity source contains the proper information to synchronize the accounts.
4.2.4 Dataflow Information
The connector for JDBC uses indirect tables to gather the needed information, ensuring that the appliance does not work directly with the information in the database. The following graphic depicts how the connector for JDBC obtains the information from the JDBC database. This process is the same regardless of the type of database to which the appliance connects.
Figure 4-1 Dataflow of User Information
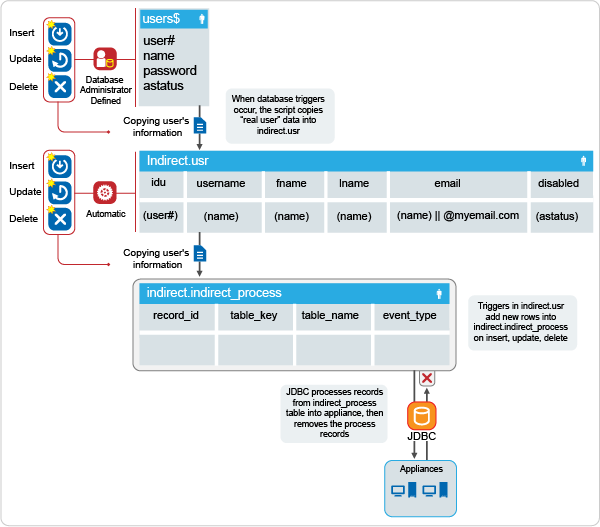
The database administrator creates the user accounts or logs in to the user$ table. (The dataflow figures are based on the default Oracle security table user$.) The database administrator defines triggers or procedures that copy information into the indirect.usr table.
The indirect_install SQL script creates the automatic insert, update, or delete triggers on the indirect.usr table. When rows in the indirect.usr table are altered, the automatic triggers add a row to the indirect.indirect_process table.
The appliance polls the indirect.indirect_process table. When the appliance detects rows in the indirect.indirect_process table of type user, the appliance adds, modifies, or deletes the user account in the applications connected to the appliance.
The appliance then deletes the row from the indirect.indirect_process table after the appliance processes the information.
Figure 4-2 Dataflow of Group Information
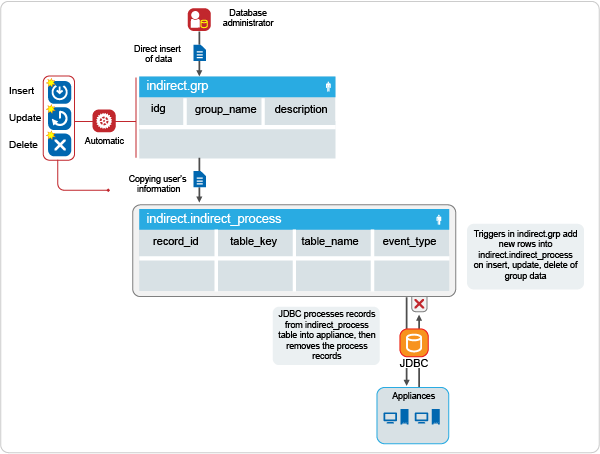
The database administrator performs a direct or triggered insert of data into the indirect.grp table.
The indirect_install SQL script creates the automatic insert, update, or delete triggers on the indirect.grp table. When rows in indirect.grp are altered, the automatic triggers add a row to the indirect.indirect_process table.
When the appliance detects rows in the indirect.indirect_process table of type group, the appliance adds, modifies, or deletes the groups in the applications connected to the appliance. The appliance then deletes the row from the indirect.indirect_process table after the appliance processes the information.
Figure 4-3 Relationship between Users and Groups
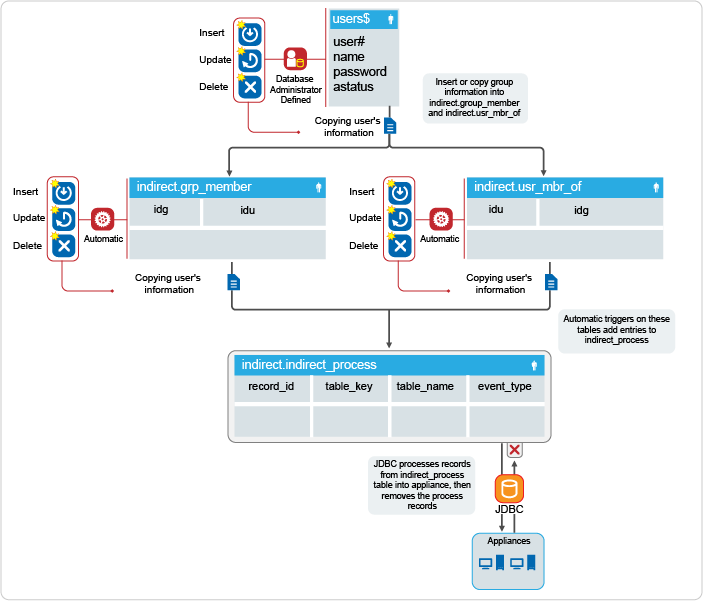
The indirect schema does not have a direct concept of group membership, but maintains a relationship between the user idu column and the group idg column in the indirect.grp_member and indirect.usr_mbr_of tables.
For group membership, the desired group idg and user idu must exist in both tables. The indirect_install SQL script creates the automatic insert, update, or delete triggers on the indirect.grp_member and indirect.usr_mbr_of tables. When rows in these tables are altered, the automatic triggers add a row to the indirect.indirect_process table.
When the appliance detects rows in the indirect.indirect_process table for group membership, the appliance adds, modifies, or deletes the group memberships in the applications connected to the appliance. The appliance then deletes the row from the indirect.indirect_process table after the connector processes the information.For example, if the administrator wants to add a user with idu 6 to a group with idg 10, the administrator would have to manually (or through triggers) add entries into both the grp_member and usr_mbr_of tables.
"INSERT INTO indirect.grp_member(idg,idu) VALUES(10,6); INSERT INTO indirect.usr_mbr_of(idu,idg) VALUES(6,10);”
Figure 4-4 Authentication Process
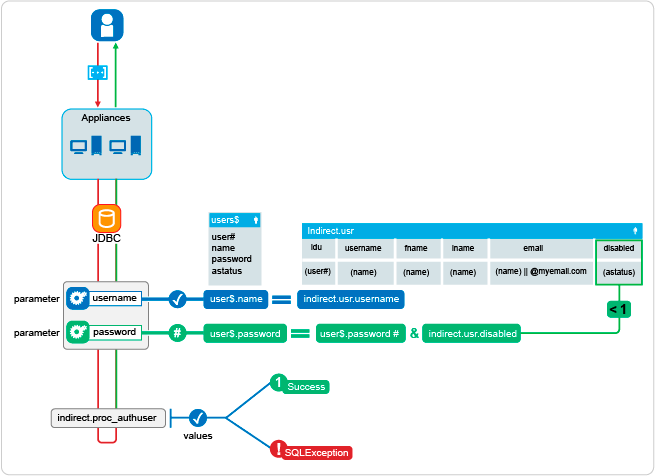
To verify authentication credentials, the appliance calls a stored procedure indirect.proc_authuser with the parameters of @username,@password. The procedure compares the username parameter with the default user table (user$) and the indirect.usr.username fields. If they match, the process checks the indirect.usr.disabled flag (disabled > 0 = disabled). If login is enabled (disabled = 0), the process compares the password parameter to the existing password hash in the user$ table. If the password hash matches, the process authenticates the user successfully. If any of these conditions are not met, the process returns a SQLException to the appliance, and authentication fails.
You can alter the stored procedure based on the desired schema that the database administrator wishes to use for authentication. Keep in mind that the stored procedure indirect.proc_authuser(@username,@password) is hard-coded into the appliance, and expects either a success (1) or SQLException returned.